 共好合同
共好合同為合同管理系統(tǒng)導(dǎo)入數(shù)據(jù)庫(kù)
在SQLserver? 服務(wù)安裝成功后,運(yùn)行 數(shù)據(jù)庫(kù)生成程序
點(diǎn)擊 Htdbcreate.exe? 右鍵 “以管理員身份運(yùn)行”
運(yùn)行后,數(shù)據(jù)庫(kù)文件會(huì)存放到 c:\sqldata 目錄下 (這個(gè)目錄現(xiàn)在不能修改),若需要將數(shù)據(jù)庫(kù)文件放到別的目錄,這個(gè)需要咨詢廠家技術(shù)人員
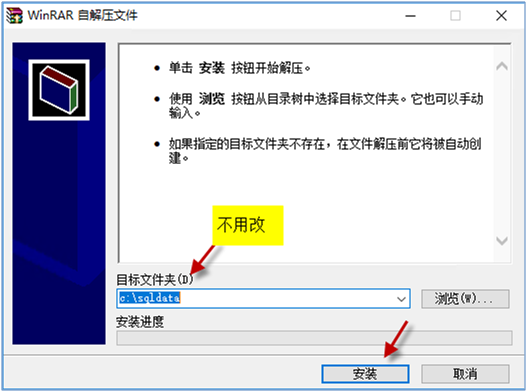
這樣,合同系統(tǒng)的數(shù)據(jù)庫(kù)就已經(jīng)安裝了
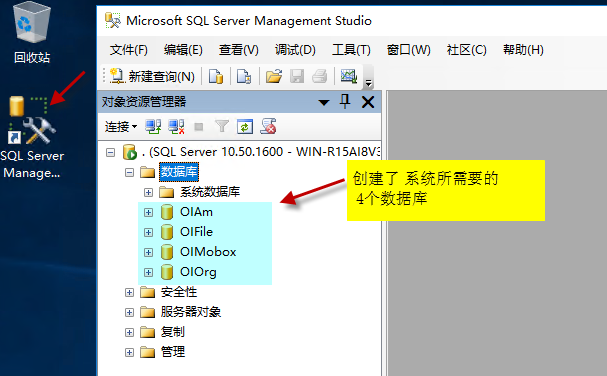
我們進(jìn)入SQL管理器能看到:
清單修改后應(yīng)該自動(dòng)更新合同總價(jià)")
共好合同軟件 – 所需系統(tǒng)環(huán)境說(shuō)明")
的Grid配置行列顯示背景色")

據(jù)對(duì)象的編號(hào)生成")
云盤30用戶免費(fèi)")
